1W - 실리움 기본 소개
개요
1주차에서는 실리움을 본격적으로 알아보기 전에 실리움이 무엇인지 알아보고 간단하게 설치하는 방법을 알아본다.
이 노트에서는 실리움이 무엇인지에 대해서만 개괄한다.
사전 지식
실리움은 ebpf를 사용하는 cni이다.
CNI
클러스터 네트워킹 과제와 CNI의 역할
쿠버네티스에서는 클러스터에서 이뤄지는 네트워킹에 대해 4가지 과제를 정의했다.

- 컨테이너 간 통신 - 파드 내부 컨테이너들은 강한 결합도를 지녀야 하며, 파드 내부에서는
localhost로 통신이 가능해야 한다.- 이것은 컨테이너 런타임에서 같은 파드의 컨테이너들을 같은 네트워크 네임스페이스에 넣는 것으로 실현된다.
- kubelet은 컨테이너 런타임에 우선적으로 pause container를 만들도록 지시하여 네트워크 네임스페이스와 같은 공유돼야 하는 자원을 고정시킨다.
- 파드 간 통신 - 클러스터 내부에서 각 파드는 고유한 IP를 할당 받으며 이 IP를 통해 클러스터 내부에서는 모든 통신이 가능해야 한다.
- 실제 노드의 IP와 관련없이 오버레이로 구성된 클러스터의 IP 대역에 대해 여러 노드의 컴포넌트들이 통신할 수 있어야 한다.
- 이것은 CNI를 통해 실현된다.
- 파드와 서비스 통신 - 서비스 역시 고유한 IP를 가지며, 서비스의 IP로 들어오는 트래픽은 연결된 백엔드 파드로 정상적으로 포워딩돼야 한다.
- 기본적으로 kube-proxy를 통해 실현되는데, 실리움에서는 다른 대안을 제시하기도 하니 무조건은 아니라 할 수 있겠다.
- 외부와 서비스 통신 - 클러스터 외부에서는 외부로 노출하도록 설정된 서비스(로드밸런서 유형)에 트래픽을 보내고 정상적인 통신이 가능해야 한다.
- 이것은 서비스의 기능을 보충해주는 각종 컨트롤러를 통해 실현된다.
간략하게 말했듯 CNI, Container Network Interface는 파드 간 통신이 가능하도록 만들어준다.
쿠버네티스 측에서는 클러스터 내부에서 이뤄지는 통신이 어떤 식으로 이뤄져야 하는지 정의하고 이를 구현할 때 필요한 인터페이스만 지정해두었다.
이 인터페이스에 맞추어 각종 커뮤니티와 기업이 다양한 기술과 각 벤더 환경에 적합한 프로바이더를 제작했다.
대표적인 CNI로 flannel, Calico, VPC CNI 등이 있고, 이번 스터디에서 공부하게 될 Cilium이 있는 것이다.
실리움은 CNI로서 다음의 기능을 제공한다.
- 클러스터 내에서 파드가 할당받을 IP를 관리한다.
- 해당 IP들을 기반으로 이뤄지는 통신에 대해 노드 내부, 혹은 노드 간 통신이 이뤄지도록 통신 경로를 제공한다.
파드 IP 할당 과정
통신 경로를 제공하는 방법, 구조에 대해서는 앞으로 자세히 다루게 될 것이고, 파드에 IP가 할당되는 과정에 대해서만 간략하게 알아본다.
파드는 노드에서 실행될 때 바로 IP를 할당받게 되는데, 구체적으로 이는 다음과 같이 도식화된다.[1]

핵심만 간단히 보자면 컨테이너 런타임이 컨테이너를 기동시키기에 앞서 자신 노드에 설치된 CNI 플러그인을 실행한다.
해당 CNI 플러그인이 설정된 방식에 따라 파드의 netns(네트워크 네임스페이스)에 IP를 할당하게 된다.
그리고 파드의 netns에서의 트래픽이 노드로 나갈 수 있도록 인터페이스를 생성해준다.
노드로 나가는 트래픽부터는 통신 경로를 만드는 부분과 관련된다.
eBPF
![]()
extended Berkely Packet Filter는 리눅스를 확장해주는 기술 중 하나이다.
복잡해져버린 리눅스 커널 스택과 독립적으로 커널 레벨에서 샌드박스 프로그램을 실행할 수 있게 해준다.
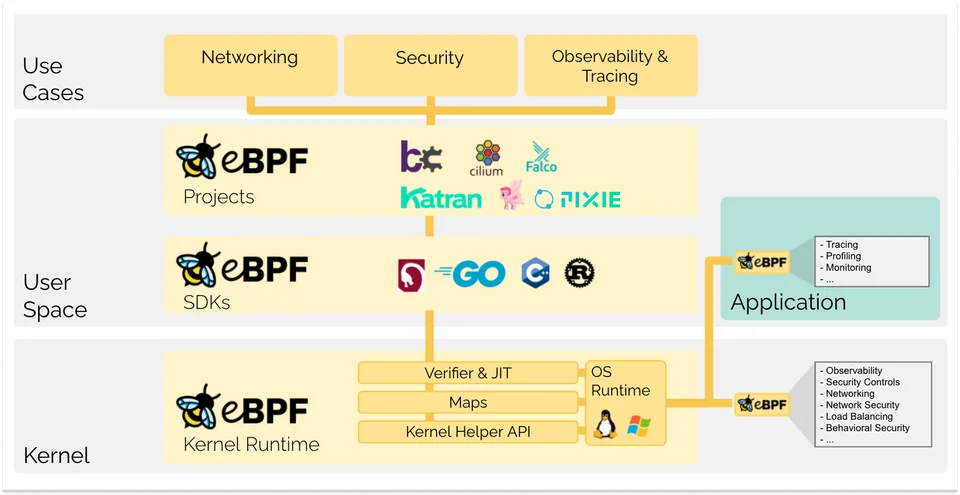
커널 정도의 특별한 권한이 있는 환경에서 샌드박스 프로그램을 실행할 수 있는 기술이다.
커널 코드나 모듈에 대한 로딩 없이 기존 커널의 기능을 안전하고 효율적으로 확장시킬 수 있다.
구체적으로 ebpf가 가지는 장점은 다음의 것들이 있다.
- 빠른 속도 - 커널 레벨에서 코드가 실행되기 때문에 불필요한 과정을 건너뛰어 원하는 기능이 빠르게 실행된다.
- 동적 로딩 - 커널을 재시작하지 않고도 원하는 코드를 런타임 중에 삽입할 수 있다.
- 안정성 - 커널 레벨에서 실행되더라도 매우 엄격한 검증을 통해 코드가 검사되어 커널을 망가뜨리지 않을 것이 보장된다.
ebpf의 배경
리눅스에서는 사용자가 만드는 모든 코드는 유저 스페이스에서 실행된다.
이 공간은 하드웨어와 자원을 직접적으로 활용하는 커널 스페이스와 분리된 공간으로, 각종 커널 레벨에서 필요한 자원을 활용할 때 syscall이라는 인터페이스를 통해 커널에 동작을 요청하게 된다.
단순하게 http 요청을 날리는 코드가 있다고 쳐보자.
conn, err := net.Dial("tcp", "example.com:80")
if err != nil {
fmt.Println("Dial error:", err)
return
}
defer conn.Close()
request := "GET / HTTP/1.1\r\n" +
"Host: example.com\r\n" +
"Connection: close\r\n" +
"\r\n"
_, err = conn.Write([]byte(request))
if err != nil {
fmt.Println("Write error:", err)
http 요청을 위해서는 먼저 tcp 커넥션을 만들어야 하고, 이 커넥션은 출발지와 목적지, 프로토콜 유형 등의 정보가 담겨있는 소켓 구조체를 필요로 한다.
이때 소켓 구조체를 얻고 통신을 보내기 위해서 socket(), 이후 connect() 등의 syscall을 내부적으로 사용하게 된다.
이렇게 리눅스에서는 커널 스페이스와 유저 스페이스를 명확하게 분리하고 유저 스페이스에서는 syscall만을 이용해 실제 필요한 동작들을 할 수 있도록 발전했다.
이러한 방식은 커널을 망가뜨릴 수 있는 임의의 코드 실행을 막아 안정성을 보장하나, 성능이나 깊은 모니터링을 하고 싶을 때 걸림돌이 되는 지점이기도 하다.
ebpf가 개발된 배경에는 결국 리눅스 커널 레벨에 대한 동작을 하고 싶다는 것이 핵심이었는데, 깊게는 네트워크와 관측성에 대한 관심이 컸다고 한다.

리눅스에서 제공하는 네트워크 플로우 다이어그램(어떤 부분에서 syscall을 할 수 있는지)인데, 딱 봐도 매우 복잡해보인다.
리눅스의 네트워크는 모뎀 시절, 그러니까 속도와 성능이 중시되지 않던 시대에서 시작해서 점차 코드가 쌓여갔다.
사용자 공간에서 활용될 수 있는 dpdk라는 툴들이 개발되었으나 이들도 상당한 제한이 많았다고 한다.
모니터링의 영역에서도 커널 레벨은 예로부터 전체 시스템을 관측하고 제어할 수 있는 이상적인 공간이었다.
그래서 관측 가능성, 보안, 네트워킹 분야에서 항상 커널을 건드리려는 시도가 많았다.
그러나 너무나도 방대해져버린 커널 진영 탓에, 개발은 항상 더딜 수밖에 없었다.
이런 상황에서 나온 게 1992년 Berkely Packet Filter로, 패킷 필터링을 확장할 수 있도록 만들어진 기술이었다.
(참고로 ebpf와 구분짓기 위해 기존의 bpf는 Classic bpf라고도 부른다고 한다.)
그리고 이것이 더 확장되면서 eBPF가 되었는데, 오늘날에는 패킷 필터링 이상의 기능을 할 수 있기에 이름은 그다지 의미는 없다고 한다.
ebpf는 간단하게만 말하면 커널에 원하는 코드를 박아넣을 수 있는 특정한 훅 포인트를 제공한다.
이를 통해 ebpf는 커널 내부에서 동작하면서 OS와 협업할 수 있으며, 커널 스택을 스킵하고 독자적인 툴로서 새로운 아키텍쳐를 세울 기반이 된다.
커널을 개발하는 진영의 지원과 개발로부터 자유롭게 원하는 동작을 커널 단에서 실행시킬 돌파구가 생긴 것이라 개발이 자유로워졌다.
애플리케이션 개발자는 각종 코드를 커널 레벨에 동작시키며 운영 체제에 추가 기능을 제공할 수 있게 됐다.
운영체제는 jit 컴파일러와 검증 엔진의 도움으로 이 프로그램들이 커널 레벨에서 안전하고 효율적으로 동작하는 것을 보장할 수 있다.
결론적으로 ebpf가 각광받는 것은, 너무나도 복잡해지고 큰 병목을 일으키는 리눅스 기본 커널 네트워크 스택에서 자유롭게 원하는 동작을 커널 레벨에서 수행할 수 있다는 것으로 이해하면 될 것 같다.
동작 방식
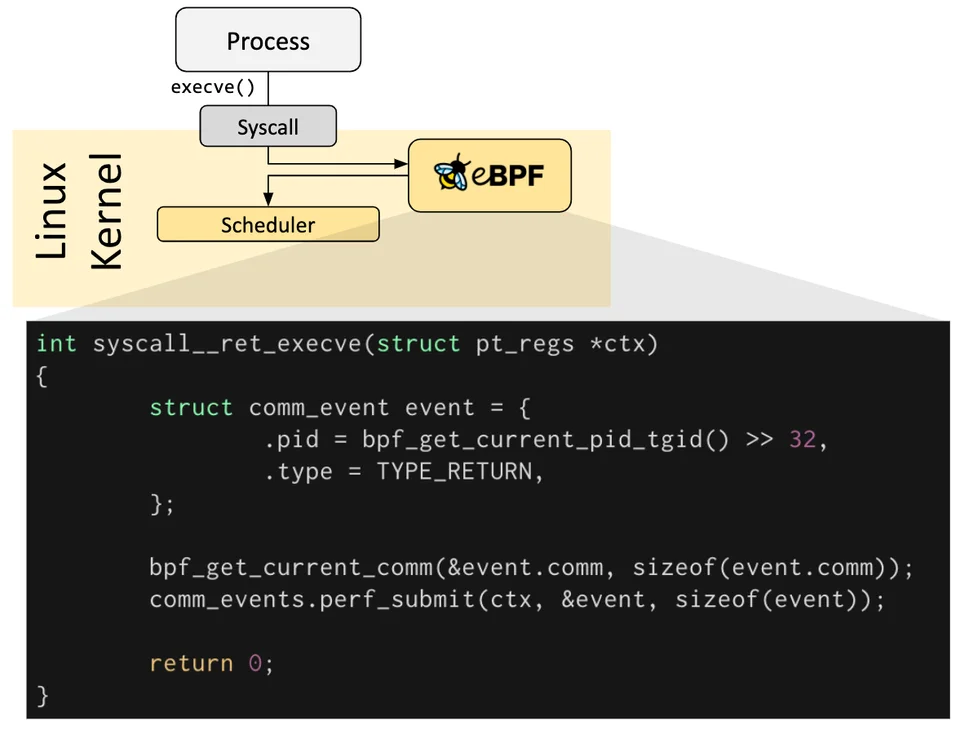
ebpf는 결국 코드를 실행시킬 수 있는 훅이다.
OS 레벨에서 특정 이벤트에 따라 훅이 발동될 때, 원하는 프로그램이 실행되도록 하는 것이다.
사전 정의된 훅들이 있어서 이때 원하는 코드가 실행되도록 해주면 된다.
만약 원하는 훅이 없다면, 커널 프로브(kprobe), 혹은 유저 프로브(uprobe)를 이용해 원하는 위치에 프로그램을 부착시켜버릴 수도 있다.
네트워크 트래픽 흐름 상으로 보자면, 아래와 같이 다양한 포인트에 훅이 존재해서 코드를 박을 수 있다.

참고로 실리움에서 핵심적으로 트래픽 관리를 위해 건드리는 부분은 아래 TC, XDP 부분이다.
Cilium
이제 본격적으로 실리움에 대해 들어가보자면,

실리움은 eBPF 기반의 CNI 프로바이더이다.
CNCF 졸업 프로젝트 중 하나로, 칼리코와 더불어 CNI로서 가장 많이 쓰이고 있다.
ebpf 관련 툴을 활발하게 만들고 있는 Isovalent 주도로 만들어지고 있다.
CNI로 출발했지만, 점차 발전하며 훨씬 다양한 기능을 제공하고 있다.

실리움으로 쿠버 로드밸런서를 세팅하는 것도 가능하고, 서비스 메시를 구축할 수도 있다..
그래서 실질적으로 실리움을 쓴다고 하면 별도의 네트워크 솔루션을 도입하지 않고 실리움의 기능들을 백번 활용하여 구축하는 케이스가 많다.
허블이란 UI 툴을 통해 모니터링을 매우 이쁘게 할 수 있다.[2]
특징
ebpf 를 사용한다는 게 그냥 특징이다.
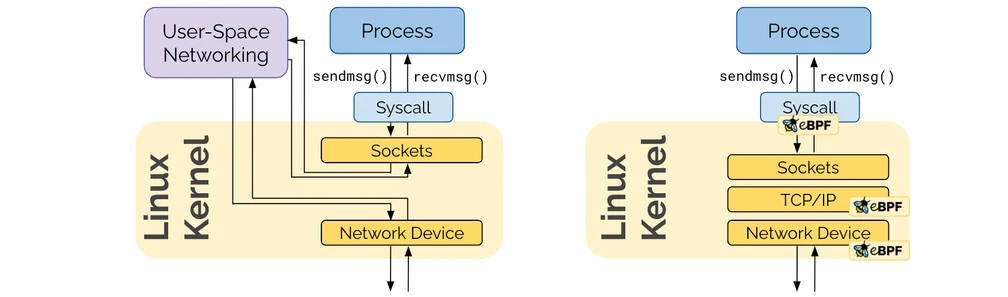
간단하게 요약되나, 이 특징이 결국 오늘날 cilium의 기본 성능과 다양한 기능들이 파생되게 해주는 근간이다.
소켓에서 인터페이스로 가는 기본적인 리눅스의 네트워크 스택을 거치지 않고, 실리움의 ebpf로 구현한 자체 경로를 통해 네트워크 기능을 수행할 수 있다.[3]
원래는 복잡하게 거쳐서 이뤄져야 했던 iptables 와 같은 영역을 전부 우회하고 실리움이 모든 기능을 커널에 임베디드된 코드를 통해 제공할 수 있다.
기능
실리움은 단순한 CNI 그 이상의 기능도 제공하는데, 각 기능들이 무엇인지 먼저 알아본다.
기본 기능 - IP 주소 관리(IPAM)
실리움은 파드의 IP 주소를 관리하는 기능을 수행한다.(사실 다른 cni들도 대체로 그렇다)
각 노드 별로 파드들이 어떤 IP대역을 가질지 다양하게 설정하는 것이 가능한데, 전체 도식으로 보면 이렇다.
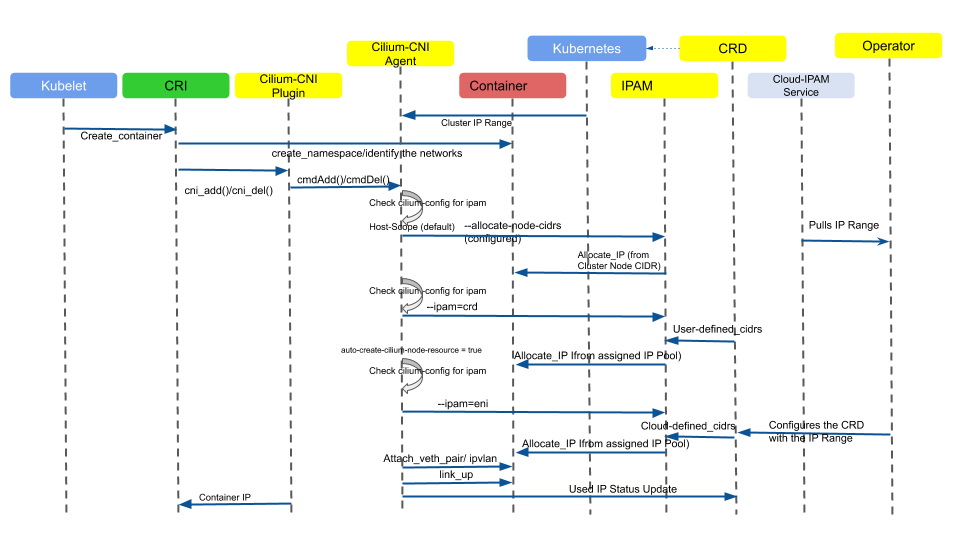
여기 나오는 것들을 한꺼번에 쓴다는 것은 아니라는 것에 유의하자.
CRI는 컨테이너를 띄울 때 CNI 플러그인을 한번 호출하는데, 이때 CNI 에이전트가 각 모드에 따라 추가적인 동작을 하며 풀에서 ip를 할당하는 원리이다.
간단하게 볼 수 있는 두 모드 정도만 살펴보자.
cluster scope
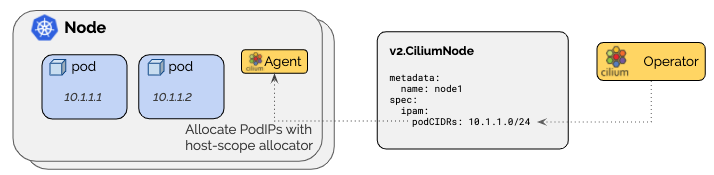
기본 모드로, CiliumNode라는 커스텀 리소스에 설정된 cidr를 기반으로 노드 별 cidr을 설정한다.[4]
아래의 kubernetes host 모드를 실리움 차원에서 한 단계 추상화한 것이라고 보면 된다.
이 리소스는 오퍼레이터가 초반에 알아서 만들어주는데 이 상태에서 알아서 조금씩 커스텀하면 된다.
이때 한번 설정된 풀 자체를 수정하는 것은 권장되지 않고, 대신 그냥 새로운 대역을 할당하는 것이 추천된다.
노드 자체, 브로드 캐스트를 위해 cidr에 두 주소를 예약해버리기에 추천되는 범위는 /29 이상이다.
kubernetes host scope
기본적으로 쿠버네티스에서는 노드 별로 파드 IP 주소를 할당한다.[5]
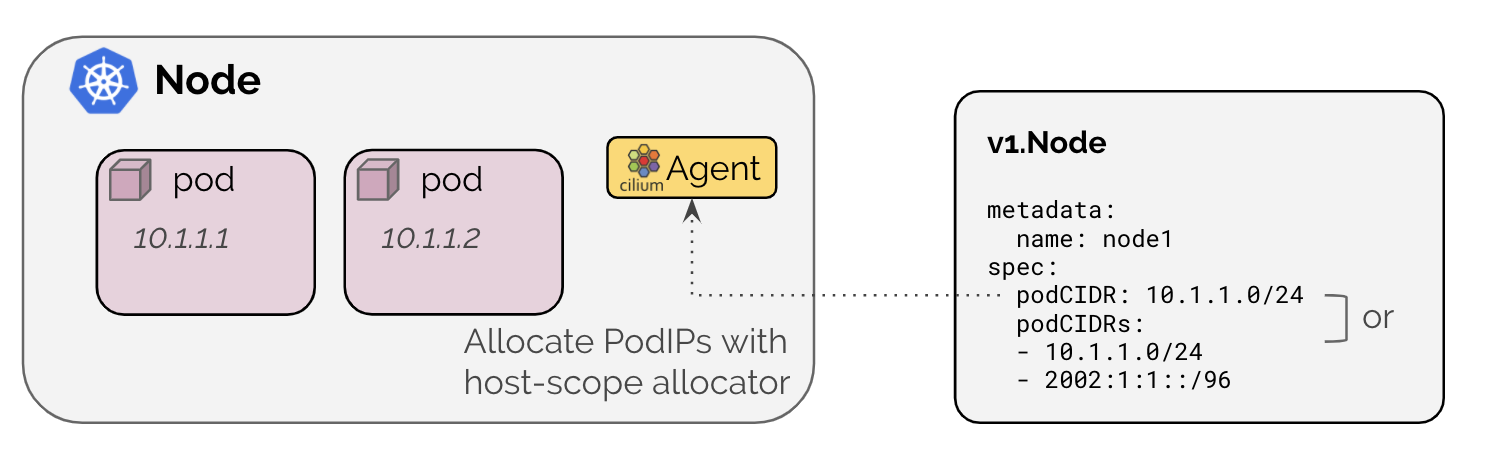
ipam: kubernetes로 설정하면 기본 노드에 할당된 cidr 값을 통해 파드의 ip를 관리해준다.(그럼 있으나 없으나..)
주의사항으로 kube-controller-manager 인자로 --allocate-node-cidrs 인자를 넣어 노드에 꼭 cidr이 설정되도록 해야 한다.
아니면 이렇게 노드에 어노테이션을 달아 직접 노드 별 cidr을 세팅하는 것도 가능하다.

다른 모드들도 많으니 문서 참고.
기본 기능 - 트래픽 라우팅
클러스터 내 파드 간 네트워킹을 전담하는 CNI로서 파드 IP로 통신이 가능하도록 트래픽을 적절히 라우팅해준다.
다른 노드 간 트래픽을 주고받기 위해 실리움은 두 가지 모드를 제공한다.[6]

캡슐 모드와 네이티브 라우팅 모드인데, 이름은 여기저기 다르지만 결국 뜻은 같다.
캡슐화(encapsulation) 모드
기본 설정으로, 파드의 트래픽을 말 그대로 터널을 뚫어서(캡슐화하여) 보낸다.
네트워크 인프라 단의 별도의 설정 없이 동작할 수 있는 모드이다.
이 모드에서는 UDP 기반의 캡슐 터널링 프로토콜이 사용된다.
VXLAN, Genvev 두 가지 프로토콜을 사용할 수 있다.
- VXLAN - Virtual eXtensible Local Area Network
- VLAN(Virtual Local Area Network)의 한계를 극복하기 위해 등장
- L2 이더넷 프레임을 L3 UDP 패킷으로 캡슐화(Encapsulation)하여 기존 IP 네트워크 위에서 터널링
- 구조
- VTEP (VXLAN Tunnel End Point) - VXLAN 터널의 시작점과 끝점 역할을 하는 장치(주로 물리 스위치 또는 서버의 가상 스위치)
- VNI (VXLAN Network Identifier) - 각 VXLAN 가상 네트워크를 고유하게 식별하는 24비트 식별자
- 약 1,600만 개의 논리적 네트워크 세그먼트를 생성할 수 있어 VLAN의 4096개 한계 초월!
- 과정
- 원본 L2 이더넷 프레임이 VTEP에 도착
- VTEP이 VXLAN 헤더(VNI 포함) 추가
- UDP 헤더(기본 포트 4789)와 외부 IP 헤더(Source IP: 송신 VTEP, Destination IP: 수신 VTEP) 추가
- 캡슐화된 IP 패킷 언더레이 물리 네트워크를 통해 목적지 VTEP로 전달
- 목적지 VTEP는 패킷에서 외부 IP, UDP, VXLAN 헤더를 제거(디캡슐화)
- 원래의 Layer 2 이더넷 프레임을 목적지 호스트에게 전달
- Geneve - Generic Network Virtualization Encapsulation
- VXLAN 및 NVGRE(Network Virtualization using Generic Routing Encapsulation)와 같은 기존 오버레이 프로토콜의 장점을 결합, 확장성 있게 설계된 프로토콜
- 과정 자체는 비슷하며, TLV(Type-Length-Value) 가변 길이 필드를 붙여 여러 옵션 데이터를 추가할 수 있음
이 방식의 장점은 다음과 같다.
- 단순함 - 별도의 설정이 요구되지 않는다.
- vxlan에서 8472, geneve에서 6081 udp 포트만 모든 노드가 오픈하고 있으면 된다.
- 파드나 노드의 cidr을 일절 신경쓸 필요가 없다.
- 주소 공간 확보 - 별도의 캡슐링을 하니 다른 주소를 침범하지 않는다.
- 신원 컨텍스트 - 캡슐화 시 신원 메타데이터를 추가하기에 서비스간 신원을 식별하여 트래픽 전달이 최적화된다.
단점으로는 MTU 부하가 존재할 수 있다.
아무래도 패킷의 양이 늘어나고 자체 크기도 커질 수 있으며, 이는 처리량의 저하를 유발할 수 있다.
점보 프레임을 활성화해 이를 완화할 수는 있다.
네이티브 라우팅(native routing) 모드
routing-mode: native를 통해 활성화할 수 있는 모드로, 노드의 라우팅 테이블을 활용한다.
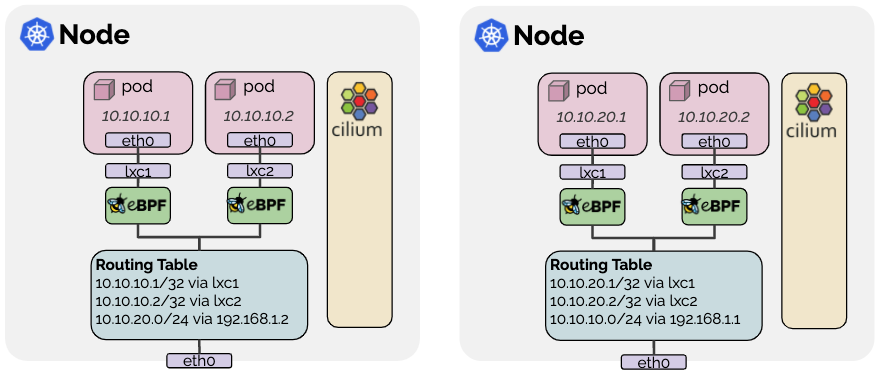
보다시피 파드마다 lxc라는 인터페이스를 부착시키고, 노드의 라우팅 테이블에 관련한 경로를 설정한다.
그래서 내부로 들어가는 주소만 아니라면 모든 패킷을 라우팅 테이블에 의해 라우팅되며, 패킷은 로컬 프로세스가 보내는 패킷처럼 다뤄진다.
그래서 패킷 포워딩 커널 파라미터가 설정돼야 하는데 이 모드를 설정하면 실리움이 알아서 세팅도 해준다. 위험한 놈
라우팅 테이블을 사용한다는 것은 노드 별로 다른 PodCIDR이 있기에 가능한 것이다.
몇 가지 제약이 있다.
- 자신 노드가 아닌 파드 주소에 대한 라우팅 시 대상 노드가 트래픽을 받을 수 있어야 함
- 노드 자신이 라우팅 경로를 알 수 없다면 별도의 라우터가 요구된다.
- 또는 각 노드가 전부 온전히 모든 노드가 가진 PodCIDR를 아는 상태로 라우팅 테이블에 반영해야 한다.
- 모든 노드가 L2에서 공유된다면,
auto-direct-node-routes: true로 가능하다. - 그렇지 않다면 BGP로 각 주소를 전파해줘야만 한다.
- 모든 노드가 L2에서 공유된다면,
참고로 이번 주차 실습에서는 네이티브 라우팅 모드를 확인해볼 것이다.
특수 기능 - kube-proxy 대체
실리움은 서비스에서 파드로 가는 트래픽 경로를 제공하는 kube-proxy를 대체할 수 있다.[7]
kube-proxy는 iptables를 이용해 서비스 ip로 온 트래픽을 파드 ip로 보내주는 역할을 해주는데 실리움을 이용하면 이걸 그냥 ebpf 단에서 쥐도 새도 모르게 처리할 수 있다..!
iptables는 대규모 클러스터에서 하나의 커다란 병목 지점이 되기 때문에 이 기능은 굉장히 큰 의미가 있다.
iptables는 구체적으로 다음의 단점을 가진다.
- 단일 트랜잭션으로 모든 규칙 업데이트 필요: iptables 업데이트는 모든 규칙을 처음부터 다시 만들어야 하는 ‘단일 트랜잭션’ 방식.
- 작은 규칙을 변경하더라도 전체 규칙 세트를 재구성하기에 규칙이 많아질수록 비효율
- 연결 리스트(Linked List)로 구현된 규칙 체인, 모든 연산은 O(n): iptables는 규칙 체인(chains of rules)을 ‘연결 리스트’ 형태로 구현
- 어떤 특정 규칙을 찾거나 적용하기 위해서는 목록의 처음부터 순차적으로 탐색하며, 모든 연산(예: 규칙 추가, 삭제, 조회, 매칭)은 복잡도 O(n)를 가진다.
- 정책이 적용될 때도 순차적이기 때문에 규칙이 많아지면 트래픽 지연 포인트가 된다.
- IP 및 포트 매칭 기반, L7(애플리케이션 계층) 프로토콜에 대한 인지 부족: iptables는 주로 패킷의 IP 주소와 포트 번호 기반 규칙 적용
- L3,4에선 효과적이나 HTTP, DNS 등과 같은 L7 프로토콜에 대한 정교한 규칙을 적용하는 데는 한계가 있다.
그렇기 때문에 수많은 서비스와 파드가 만들어졌다 사라졌다 하는 쿠버네티스 환경에서 성능 병목 지점이 된다.
규모가 큰 클러스터에서 서비스 하나가 생성되면 제대로 기능을 하기까지 수분의 시간이 소요될 수도 있다.
그러나 ebpf를 활요하는 실리움에서는 정책 적용, 라우팅을 훨씬 효율적으로 수행할 수 있다.
이후에 볼 소켓 레벨 로드밸런싱 등을 통해 실리움은 더 효율적으로 트래픽 경로를 수정한다.
이밖에 bgp 연계, 클러스터 메시 구성, 신원 관리 및 정책 등 다양한 기능이 있으나 당장 이번 주차에서 다룰 내용으로만 한정짓고자 여기에서는 다루지 않는다.
구조
아래 그림은 실리움이 커널에 bpf로 접근해 각종 조작을 수행하는 전반 구조를 담고 있다.
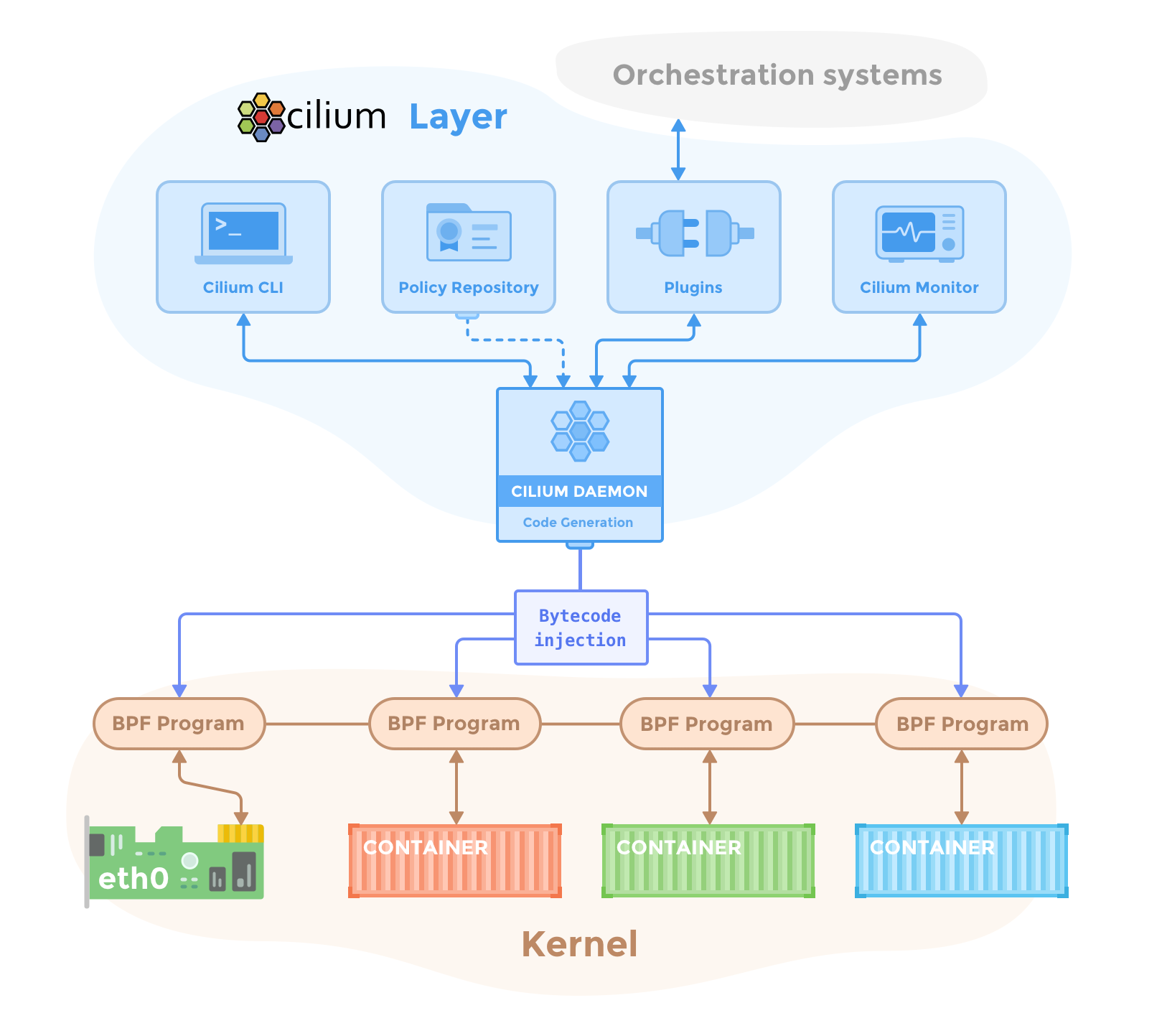
구체적으로 실리움의 구성 요소는 다음과 같다.
참고로 CNI로서의 실리움은 간단하게 에이전트와 오퍼레이터가 있다 정도만 알아도 된다.
- 실리움
- 에이전트 - 데몬셋
- kube-apiserver의 설정을 감시하며 노드 워크로드에 대해 각종 기능을 수행한다.
cilium-dbg라는 이름의 cli 툴이 디버그 클라이언트로 내부에 같이 들어있다.- rest api 통신으로 각종 디버깅 요청 처리
- 에이전트의 상태, 노드의 ebpf 맵 상태 조회
- 오퍼레이터 - 실리움 관련 커스텀 리소스를 추적하여 설정 반영
- 각종 실리움의 기능을 활용하는데 있어서는 필수적이나, CNI로서 필수는 아니다.
- 에이전트 - 데몬셋
- 허블
- 데이터 스토어
- 이건 뭐 별도로 존재한다는 건 아니고 실리움이 동작하는데 있어 에이전트 설정 및 상태 전파에 활용되는 데이터 객체를 말한다.
- 당연히 커스텀 리소스가 기본인데, 키값쌍 방식으로 설정을 저장하는 게 가능해서 그냥 Etcd에 바로 접촉해 필요한 데이터를 저장하는 방식도 지원한다.
용어
실리움에서 사용되는 몇 가지 개념들과 함께 간단한 용어들을 미리 알아두면 문서를 이해하는데 도움이 된다.[8]
라벨
라벨은 어떤 리소스를 나타내는 수단으로, 셀렉팅의 대상이 되거나 신원 식별, 네트워크 정책 수립 시 사용된다.
쿠버네티스에서 흔히 사용되는 그 라벨이 맞는데, 다른 것도 라벨이 될 수 있다.
containers, k8s, reserved, unspec 등의 유형이 있으며 이는 라벨의 소스를 기반으로 매겨진다.
소스가 명시 안되면 any로 받는다.
엔드포인트
IP의 단위를 말하는데, 쿠버 관점에서 보면 그냥 하나의 파드를 말한다(한 파드가 하나의 ip를 가지니까).
그러나 실리움에서는 노드도 하나의 엔드포인트로 취급되며 여기에 헬스체킹용 엔드포인트와 같은 특별한 대상도 존재한다.
위의 라벨이란 것은 이 엔드포인트에 붙는 메타데이터이다.

아이덴티티
라벨의 일부 유형으로, 엔드포인트의 신원을 나타낸다.
기본적으로 이것도 L3 IP와 지위가 크게 다르지 않다.
신원은 클러스터 내에서 고유한데, 보안 관련 라벨로 신원을 분류할 수도 있긴 하다.
몇 가지 특수한 아이덴티티도 있는데, 실리움으로 관리되지 않으나 엔드포인트 통신을 위해 활용할 수 잇는 아이덴티티이다.
reserved라는 접두사가 붙는다.
- reserved:unknown
- 0 - 신원을 유추할 수 없다
- reserved:host
- 1 - 로컬 호스트의 트래픽
- reserved:world
- 2 - 클러스터 외부 임의의 엔드포인트
- reserved:unmanaged
- 3 - 쿠버 내 엔드포인트이나, 실리움의 관리를 받지 않는 엔드포인트
- reserved:health
- 4 - 실리움 에이전트 헬스체킹 트래픽
- reserved:init
- 5 - 신원을 받지 않은 초기화 당시의 신원.
- 신원 확보에 필요한 메타데이터가 아직 없는 상태의 엔드포인트가 부여 받으며, 흔히 부트스트랩 단계에만 존재한다.
- 초기 신원은 생성 시기에 엔드포인트 라벨을 알 수 없을 때만 할당되는데, 보통 도커 플러그인이 그렇다.
- reserved:remote-node
- 6 - 원격 클러스터 호스트 집합
- reserved:kube-apiserver
- 7 - 원격 중 api 서버가 가동 중인 노드
- reserved:ingress
- 8 - 인그레스 프록시를 위한 엔드포인트
이것들 말고도 부트스트래핑, 혹은 클러스터의 코어 컴포넌트들을 위한 신원도 있다.
이것들은 well-known 이라 하여, 실리움 세팅 이전에 있는 대상들에 대해 부여하는 아이덴티티이다.
아이덴티티는 기본적으로 키값 저장소를 통해 관리된다.
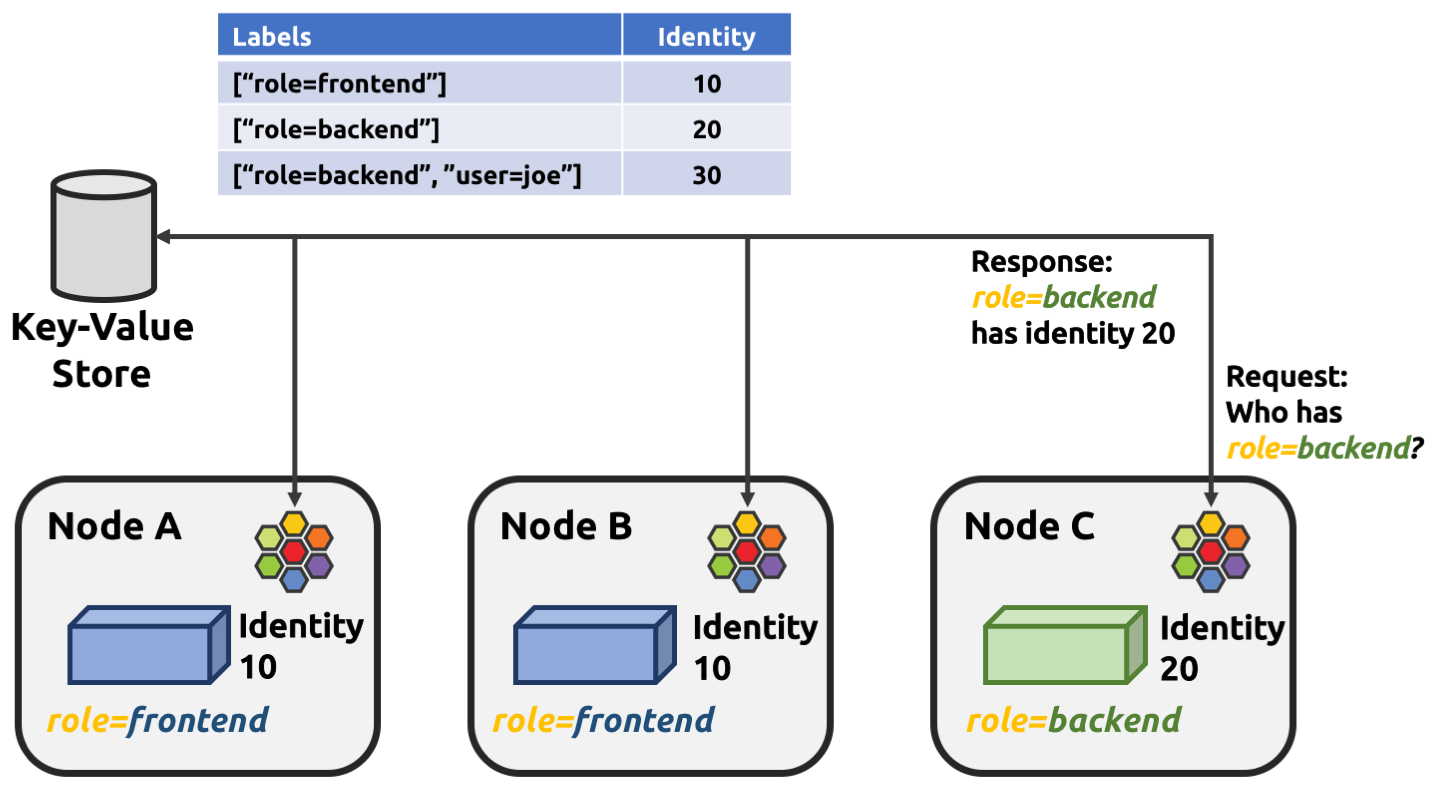
본 적 없는 신원은 새로 식별자가 생성된다.
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - 실리움 기본 소개 | 1 | published | 2025-07-19 |
| 1W - 클러스터 세팅 및 cni 마이그레이션 | 2 | published | 2025-07-19 |
| 1W - 기본 실리움 탐색 및 통신 확인 | 3 | published | 2025-07-19 |
| 2W - 허블 기반 모니터링 | 4 | published | 2025-07-26 |
| 2W - 프로메테우스와 그라파나를 활용한 모니터링 | 5 | published | 2025-07-26 |
| 3W - 실리움 기본 - IPAM | 6 | published | 2025-08-02 |
| 3W - 실리움 기본 - Routing, Masq, IP Frag | 7 | published | 2025-08-02 |
| 4W - 실리움 라우팅 모드 실습 - native, vxlan, geneve | 8 | published | 2025-08-09 |
| 4W - 실리움 로드밸런서 기능 - 서비스 IP, L2 | 9 | published | 2025-08-09 |
| 5W - BGP 실습 | 10 | published | 2025-08-16 |
| 5W - 클러스터 메시 | 11 | published | 2025-08-16 |
| 6W - 실리움 서비스 메시 - 인그레스 | 12 | published | 2025-08-23 |
| 7W - 실리움 성능 - 쿠버네티스 기본 | 13 | published | 2025-08-31 |
| 8W - 실리움 보안 | 14 | published | 2025-09-07 |
관련 문서
지식 문서, EXPLAIN
| 이름5 | is-folder | 생성 일자 |
|---|---|---|
| 설치 요구사항 | false | 2025-07-06 10:34 |
| Hubble | false | 2025-07-06 10:38 |
| ebpf 동작 가이드 | false | 2025-07-06 10:49 |
| 0주차 검증 | false | 2025-07-06 12:46 |
| Cilium | false | 2025-06-15 23:42 |
기타 문서
Z0-연관 knowledge, Z1-트러블슈팅 Z2-디자인,설계, Z3-임시, Z5-프로젝트,아카이브, Z8,9-미분류,미완| 이름21 | 코드 | 타입 | 생성 일자 |
|---|---|---|---|
| 8W - 실리움 보안 | Z8 | published | 2025-09-07 12:22 |
| 실리움 1주차 | Z8 | topic | 2025-07-13 19:50 |
| 실리움 개괄 | Z8 | topic | 2025-07-19 11:00 |
| 클러스터 세팅 및 cni 마이그레이션 | Z8 | topic | 2025-07-19 10:13 |
| 기본 실리움 탐색 및 통신 확인 | Z8 | topic | 2025-07-19 23:05 |
| 실리움 2주차 | Z8 | topic | 2025-07-20 19:05 |
| 노드로컬 dns | Z8 | topic | 2025-08-02 12:57 |
| 실리움 3주차 | Z8 | topic | 2025-07-27 19:44 |
| 1W - 클러스터 세팅 및 cni 마이그레이션 | Z8 | published | 2025-07-19 23:38 |
| 3W - 실리움 기본 - IPAM | Z8 | published | 2025-08-02 19:48 |
| 1W - 기본 실리움 탐색 및 통신 확인 | Z8 | published | 2025-07-19 23:45 |
| 3W - 실리움 기본 - Routing, Masq, IP Frag | Z8 | published | 2025-08-02 22:23 |
| 4W - 실리움 로드밸런서 기능 - 서비스 IP, L2 | Z8 | published | 2025-08-09 21:56 |
| 4W - 실리움 라우팅 모드 실습 - native, vxlan, geneve | Z8 | published | 2025-08-09 20:22 |
| 5W - BGP 실습 | Z8 | published | 2025-08-16 22:21 |
| 5W - 클러스터 메시 | Z8 | published | 2025-08-16 23:25 |
| 7W - 실리움 성능 - 쿠버네티스 기본 | Z8 | published | 2025-08-31 00:53 |
| 6W - 실리움 서비스 메시 - 인그레스 | Z8 | published | 2025-08-23 13:56 |
| Cilium 공식 문서 핸즈온 스터디 | Z8 | published | 2025-07-05 20:47 |
| 2W - 프로메테우스와 그라파나를 활용한 모니터링 | Z8 | published | 2025-07-26 21:15 |
| 2W - 허블 기반 모니터링 | Z8 | published | 2025-07-26 21:08 |
참고
https://docs.cilium.io/en/stable/observability/hubble/#hubble-intro ↩︎
https://cilium.io/blog/2020/11/10/ebpf-future-of-networking/ ↩︎
https://docs.cilium.io/en/stable/network/concepts/ipam/cluster-pool/ ↩︎
https://docs.cilium.io/en/stable/network/concepts/ipam/kubernetes/#k8s-hostscope ↩︎
https://docs.cilium.io/en/stable/network/concepts/routing/ ↩︎
https://docs.cilium.io/en/stable/network/kubernetes/kubeproxy-free/ ↩︎
https://docs.cilium.io/en/stable/gettingstarted/terminology/ ↩︎